Here we are, the end of June and so much progress, not much blogging.. still heres a succient update.
Research Ethical Approval
As a post graduate researcher I have to ensure my research is ethical and approved by the University. Bournemouth university provide an extensive ethics checks list to which I have to review and provide the necessary information. Essentially I have to provide details to ensure that what I am doing is not 1) illegal 2) ethically unsound.
I was able to provide all the required evidence to show my data acquisition, storage and use, ensuring that at no point that my research would encroach on the public domain. After completing all the forms and submitting I was please that my research was approved and I could safely use and store data in the way I had given.
What is important here is that *if* my data has been acquired outside of my lab, i.e. there is plenty of abundant RF sources of IoT devices available, this would of been far more involved. The more you engage with external environments/people, leave plenty of time to write up your ethics and data plan !
TL/DR – Even in a “simple” research lab, getting ethical approval is essential, and takes time to complete. Allow plenty of time ahead of starting your research to get ethical approval to allow to start collecting and using data.
Lab updates
So alot of my time has been spent on building the lab up. This involves data acquisition, processing and user interfaces. I’ll do a short summary of each
- Aquisition
- Chipwhisperer updates
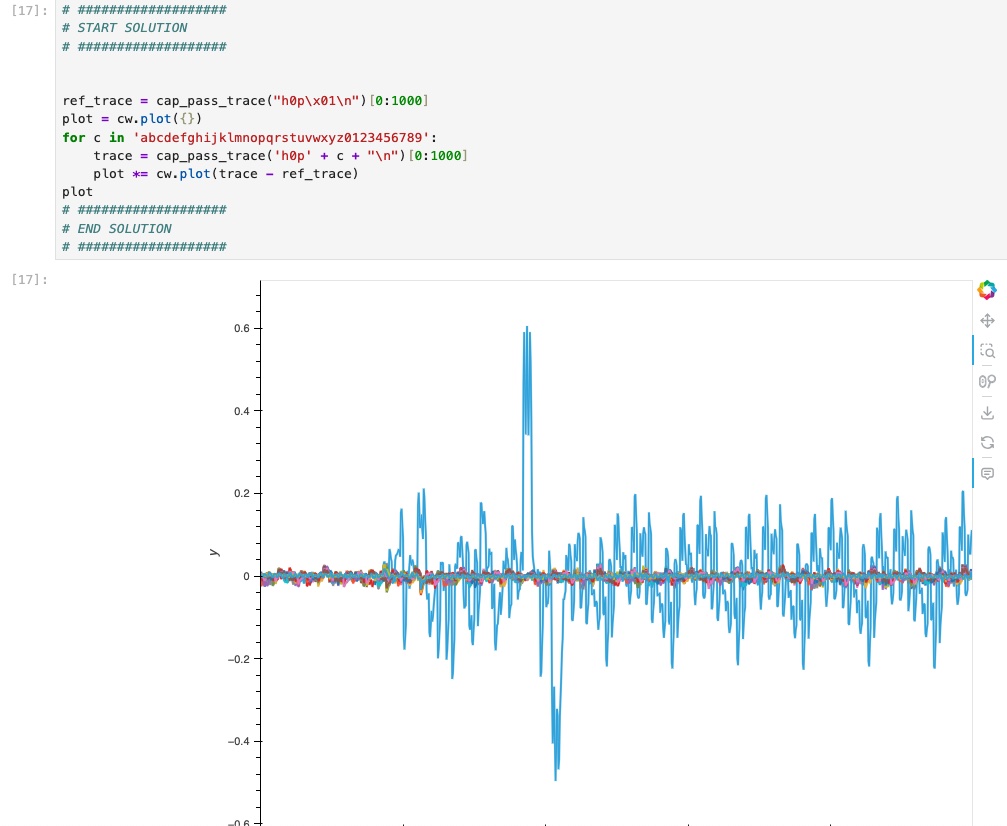
- I’ve had the chipwhisperer and boards since my MSc in 2022, there have been quite a few updates in this time so I’ve updated my board and software. Safe to say that I’m excited that everything is working well and tested the board out to get AES traces from the board and run the example test labs from Juypter notebooks, show here is DPA to obtain a password.
- Chipwhisperer updates
- Slurm Cluster
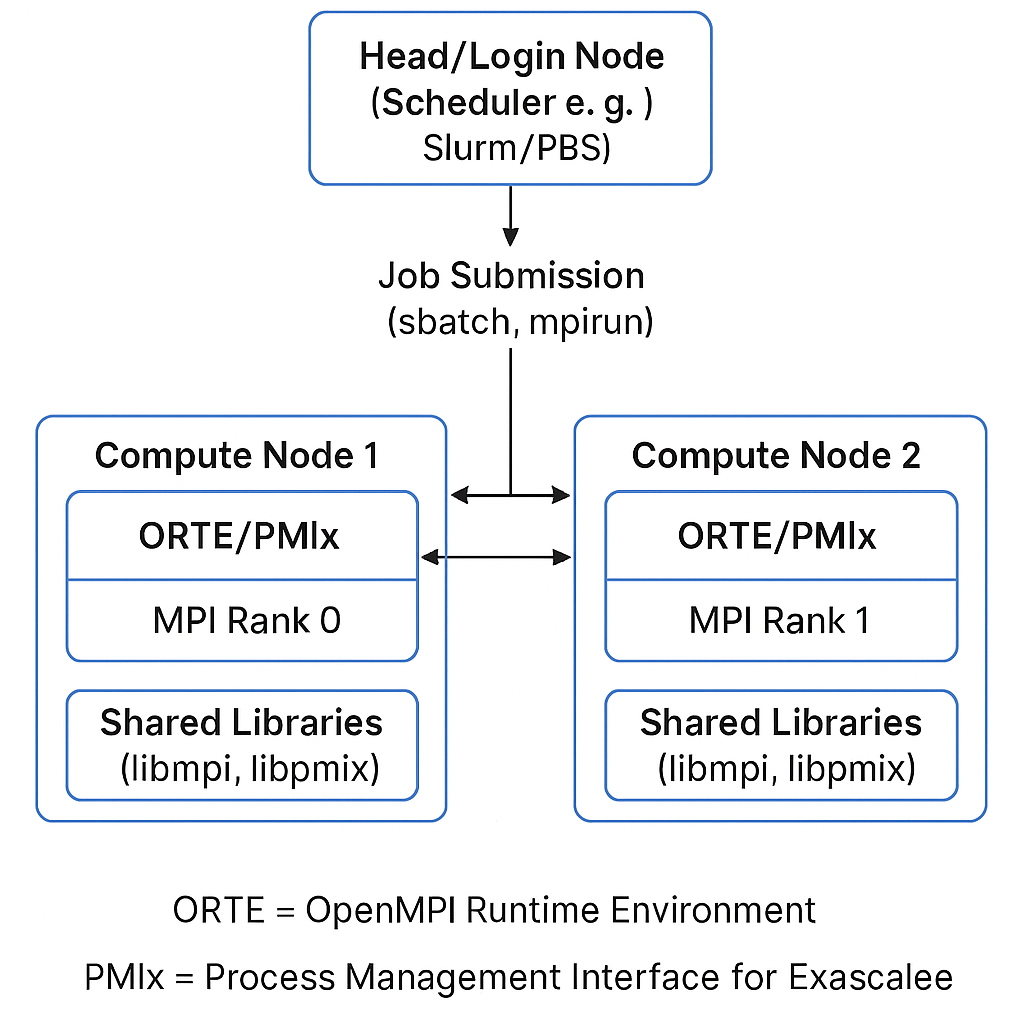
- MPI + PMIX
- OpenMPI and PMIX has been added to the slurm cluster. As I have now have 3 GPU Nodes with a variety of GPU’s (P40/P100/RTX3050) and want the ability to mesh between them , i.e. training on the P40’s, inference on the P100s, 3050 for general use) and to pass messages between the nodes as needed. MPI allows parallel the processes running on different nodes to communicate with each other. This combines with PMIx to manage the processes between the nodes. What’s really cool about this, is that i can recognize the bottle necks in my setup, i can still leverage as many or as few GPU’s as I like thanks to the new partitioning schema. If want to do a batch train and then use that model i can setup the slurm job and python script to go from training/inference. This will be very useful when doing hyperparameter tuning and classification validation.
- MPI + PMIX
- Array/Parittion/QoS
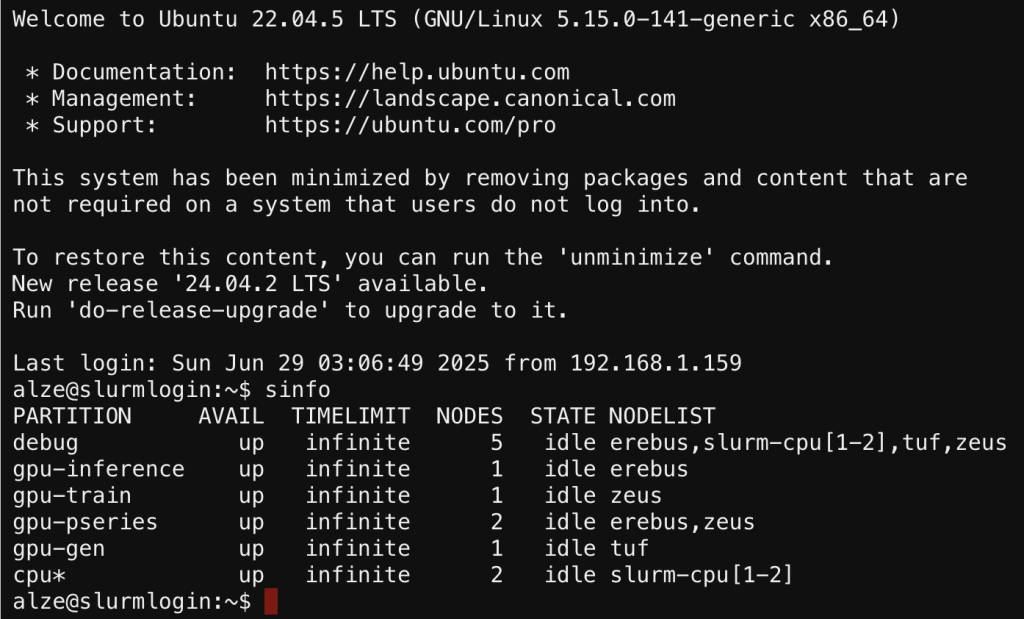
- With a variety of GPU and CPU types in the cluster I wanted to add more specificity, in slurm this is handled via general resource allocation (GRES) and assigning nodes to various partitions. For my research i generated the following
| partition | nodes | nodelist |
| debug | 5 | erebus,slurm-cpu[1-2],tuf,zeus |
| gpu-inference | 1 | erebus |
| gpu-train | 1 | zeus |
| gpu-pseries | 2 | erebus,zeus |
| gpu-gen | 1 | tuf |
| cpu* | 2 | slrum-cpu[1-2] |
I’m now able to define in my slurm batch or srun which GPU/CPU partition to use. To prove everything was running well, i setup a simple ‘multinode’ job which evidenced which node was being utilized for the task.
#!/bin/bash
#SBATCH --job-name=my_array_test
#SBATCH --output=logs/job_%A_%a.out
#SBATCH --error=logs/job_%A_%a.err
#SBATCH --array=1-1000
#SBATCH --ntasks=1
#SBATCH --time=00:10:00
#SBATCH --mem=1G
#SBATCH --partition=debug
echo "Running job array task ${SLURM_ARRAY_TASK_ID} on node $(hostname)"
sleep $(( RANDOM % 30 ))
I could run squeue to see all the nodes in the ‘debug’ parititon fully used
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
4066_[146-1000] debug my_array alze PD 0:00 1 (Resources)
4066_142 debug my_array alze R 0:01 1 erebus
4066_143 debug my_array alze R 0:01 1 tuf
4066_145 debug my_array alze R 0:01 1 slurm-cpu2
4066_137 debug my_array alze R 0:04 1 zeus
4066_138 debug my_array alze R 0:04 1 slurm-cpu2
4066_139 debug my_array alze R 0:04 1 erebus
4066_141 debug my_array alze R 0:04 1 erebus
4066_132 debug my_array alze R 0:07 1 slurm-cpu1
Whilst I’m the sole user of the cluster, it is netherheless good to get familiar with accounting and QoS, one thing to consider is that I don’t have the cluster running full-tilt during the day time when I’m working as with all the fans on it can get quite noisy. I do aim to sort out the environmental conditions in due course, but requires a whole lab move to do so.. I setup a simple MariaDB for the accounting data and simple QoS patterns
acctmgr list account format=Name,Description,Organization
Name Descr Org
---------- -------------------- --------------------
mylab account mylab
prolab account prolab
reslab account reslab
default root account root
test accounts knipmeyer-it
unrestricted access unrestricted The slurm account management tool ‘sacct’ can produce really good reports on usage, its possible to see the allocated amount of CPU/GPUs and time used. In a real-life cluster (such as SCW) the amount of GPU’s requested for a batch job leads to longer wait times for those GPU’s to become available. For me, i have no such QoS setup as yet, but I now familiar with how to set this up.
- Slurm WebUI – OnDemand with DEX / LDAPS
Whilst having ssh/cli access via native clients is fine, having a WebUI to interface with allows use of the lab from any location i can acesss the lab from. To enable a more ‘user friendly’ interface to the slurm cluster I installed ‘open ondemand’. To acheive this i basically clone a login node where I would ssh into and run the slurm command line tools (sbatch/srun,etc) and add the Open OnDemand packages. Because I already have LDAP(S) and shared home directories setup on the cluster, it was a case of getting ondemand and Dex to speak to the LDAP server, this took quite a bit of time, but nether the less a few hours of googling/reading documentation lead to a working configuration ! Whilst I still have alot more to learn about adding more templates/jobs and interactive apps to OnDemand, I’m really pleased with the WebUI.
Login screen to OnDemand using my LDAP Credentials
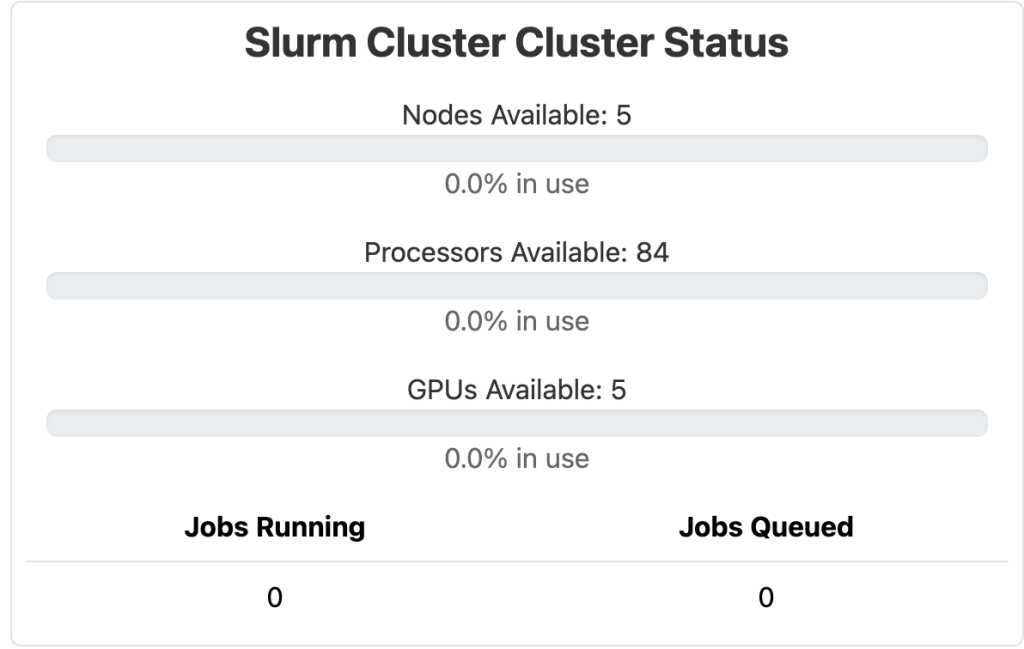
Slurm Custer Status
File browser (with upload !)
Interactive Shell to Login node
I’m planning on putting a reverse proxy / nginx with SSL in front so I can access the OnDemand portal from ouside of the lab and put suitable hardening/IP whitelisting to allow access.
External Engagements – Ches Challenge 2025
So as I now have the cluster setup, I thought it fun to try a live challenge on it. The CHES Challenge 2025 involves cryptanalysis using Python, and introduces some interesting problems to overcome. Whilst the datasets are provided and labeled, they are containing noise and jitter – in my own lab I aim to remove these before pre-processing, in a real world environment of side channel attacks, its more likely to have these and then provide software solutions in the training phase to overcome noise and jitter in the electromagnetic trace collections.
So far I have written functions for jitter and noise, but am facing the classic issue of oversizing, so my results are still way off, but nethertheless I am not discouraged. I am working on limiting the amount of epochs based on the % of fit and results, which should reduce the data becoming only as good or worse than brute-force/random attacks.
Whilst the contest is still live and finshes on August 15th, I will share what I have learned after that time 🙂
train Epoch Loss: 0.0275 Epoch Acc: 0.9974
val Epoch Loss: 11.2832 Epoch Acc: 0.201Its oversizing… :\
Progressing the literature review
So when I’m not programming, building out new features in the lab, I’m reading. Alot of reading. Part of this is build knolwedge and references for the all important literature review section of the thesis. Work on this is goes on across the whole thesis writing stages almost up until the viva/defence.
I took a recent publication which reviews many types of encryption attacks by zunaid (bibtex ref below).
The whole publication is excellent, almost a ‘readers digest’ of recent cryptanalysis publications. Whilst I read thru the paper, the excellent appendix containing the information into a tabulated format. I transposed this to Excel and then filtered them, from this it gave me an excellent set of publications to read through and provide substance to my lit review.
@article{zunaidi2024systematic,
title={Systematic Literature Review of EM-SCA Attacks on Encryption},
author={Zunaidi, Muhammad Rusyaidi and Sayakkara, Asanka and Scanlon, Mark},
journal={arXiv preprint arXiv:2402.10030},
year={2024}
}50+ Part-Time PGR – Wellbeing
So I’m into my 50’s now, as well as working 9-5 I make time every single day to get more research activities in. This leads into alot of desk time, if I dont tell myself this is easily 18-19 hours (i’m not making this up..) at my desk with a break for walking the dog and the routine things. As ever, this has lead to increase to my weight, poor back posture (aches and pains) and overall just not being as fit as I should.
Bournemouth University has an excellent gym, being a sports-science university, it has more than the usual running machines and weights. I’m going to check it out and hopefully get into a work-out regime I’ve not had in over 10 years, and looking forward to getting a bit fitter and feeling better in myself !
Well, this has taken me longer than I thought to write up, I’ve probably missed loads, but I think this is good for now 🙂